
Jiho Sim
Ph.D. Student, Seoul National University
j2hosim@snu.ac.kr
AI-Co-Scientist
A Multi-Agent Framework for Autonomous Scientific Discovery (2025)
1st Place, Bio-AI Co-Scientist Competition (Dec 2025). Hosted by the AI-Bio Institute, SNU and IITP (Ministry of Science and ICT). Judges: Peter Frazier (Cornell), Masashi Sugiyama (RIKEN/UTokyo), Hyeshik Chang (SNU), Soo Seok Hwang (SNU), Chaok Seok (SNU/Galux).
Abstract
We built a a multi-agent AI system designed to address complex biomedical research questions through autonomous collaboration. A Principal Investigator (PI) agent coordinates specialized agents — integrating computational analysis, literature search, and database queries — under the adversarial oversight of a Critic agent. The competition had two categories, server (with short time limit) and human (with longer time limit, allowing human intervention). For the Server Category, we submitted fully automated responses generated by the framework, using diverse LLMs and an LLM-as-a-judge protocol for quality selection. For the Human Category, we used a cross-model validation protocol: outputs from multiple LLMs were systematically cross-referenced, checked for hallucinations against raw data, and iteratively refined. Human intervention focused on orchestrating verification, not on direct content modification.
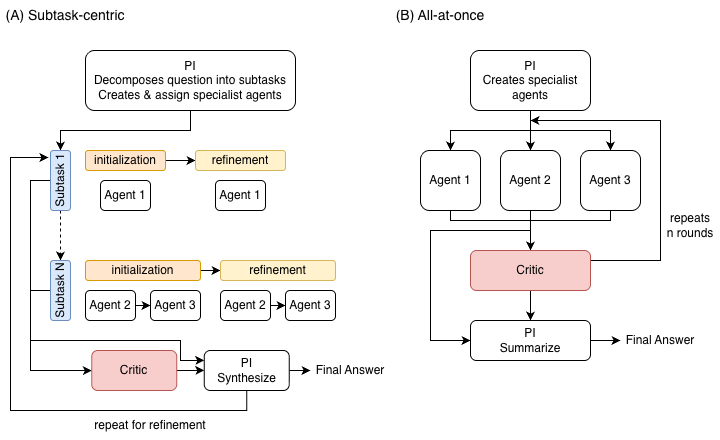
System architecture
Two modes:
- Subtask-centric. The PI analyzes required expertise, designs a specialist team (e.g. Computational Biologist, Immunologist, Data Scientist), and decomposes the question into 3–5 sequential subtasks with explicit dependencies. Specialists generate and refine answers; later subtasks receive complete context from earlier ones for cumulative knowledge. After each round, a Critic generates a structured issue checklist that the PI must resolve in the final synthesis.
- All-at-once. Specialists are still defined dynamically, but each agent answers the whole question in parallel within a single round. The Critic then reviews and compares answers to resolve conflicts or unsupported claims.
Tool integration
Each agent has access to: execute_python (data analysis, plotting); search_literature (RAG over local PDFs plus PubMed, arXiv, Semantic Scholar via PaperQA); query_database (DrugBank, BindingDB, STRING, GWAS Catalog); and read_file / find_files for navigating intermediate results. Agents choose tools autonomously until satisfied with the answer.
Evaluation
An LLM-as-a-judge system (FastChat-style) scores answers on a 1–10 scale across six criteria: Scientific Accuracy (30%), Evidence Quality (20%), Methodological Rigor (15%), Completeness (15%), Clarity (10%), Critical Thinking (10%). Pairwise comparison picks winners between answer variants, enabling systematic selection across pipeline modes and model providers.
Categories
- Server Category. Each problem ran fully automatically (apart from manual download of paywalled PDFs). We ran the pipeline in both modes across three LLMs (gemini-3-pro, claude-sonnet-4.5, gpt-5.2) with defaults
team-size=3, max-iterations=30, rounds=2. When multiple outputs were generated, pairwise evaluation selected the highest-quality answer. - Human Category. A systematic protocol emphasizing cross-model validation rather than direct human correction. Human work focused on (1) orchestrating which models receive which inputs, (2) detecting hallucinations by cross-checking outputs against raw data, and (3) guiding synthesis of complementary findings. Scientific analysis stayed AI-generated.
Highlights per problem:
- P1 (Ribo-seq). Qualitative diagnosis decomposed from computational analysis; agent outputs cross-validated against direct model execution before selection.
- P2 (TERRA). Direct Python execution disabled to mitigate fabrication; the problem statement was restructured and meeting prompts refined for holistic context. Gemini Pro made the final selection.
- P3 (GLP-1R). Five model outputs converged via pairwise comparison on ActRIIB/Myostatin and GIP-receptor pathways as primary targets — compensatory nodes for GLP-1’s failure points. Human contribution: pathway visualization.
- P4 (Multi-part). Three sub-questions executed serially with context passing; refinement via Claude web interface accepted only when evaluation confirmed improvement.
- P5 (T-cell exhaustion). Full protocol in action. Claude Opus 4.5 and Gemini Pro produced complementary analyses from identical raw data, mutually cross-verified. Hallucinated values (fabricated gene IDs
GM42878,DUXBL3; incorrect DEG counts) were caught and removed, while valid conceptual insights — e.g. the “biphasic exhaustion” hypothesis — were preserved.
Takeaway
Structured workflows plus adversarial review let multi-agent systems answer research-level questions. LLM web-assistants used as mutual fact-checkers reliably catch hallucinations while preserving valid insights, suggesting AI can serve as a research collaborator when the verification machinery is in place. Difficulty came from balancing novelty and accuracy. For problems like P5, the competition judges commented how none of the competitors provided a truly novel insight. We are working on improving the system’s ability to generate novel hypotheses while maintaining scientific rigor (keep an eye out for our upcoming workshop proposal on this topic!).
References
- Swanson, K. et al. The Virtual Lab of AI agents designs new SARS-CoV-2 nanobodies. Nature 646.8085 (2025): 716–723.